Building an Eval System for My Autonomous AI Agent
Published on 04.04.2026

TLDR:
My autonomous AI agent running on a QNAP NAS was great at simple one-shot tasks but fell apart in multi-turn conversations. Each heartbeat is a fresh CLI invocation with no persistent memory beyond what I manually inject as context. Before improving the context pipeline, I needed a way to measure whether changes actually help. So I built a TypeScript eval system that exercises the real bash context pipeline against real AI providers. It immediately revealed both context quality issues and an orchestrator bug I didn't know existed.
The Problem: Fresh Context Every Beat
If you've read my previous article about setting up the agent on the NAS, you know the architecture: cron fires, bash polls Telegram, dispatches the message to Claude Code (or Gemini, Qwen or whatever provider you've configured), and posts the response back. Simple, effective, zero dependencies beyond bash, curl, and jq.
The catch is that every heartbeat is a completely fresh execution. Agent cli starts with zero context, it doesn't remember anything from the previous turn. The only continuity comes from what I call the "system context": a block of text I prepend to every prompt containing the conversation history, global memory, and instructions.
For simple tasks, "create a file," "run this command," "what's in this directory", it works brilliantly. But the moment a conversation requires three or four turns of back-and-forth, the agent starts losing the thread. It would re-ask questions I'd already answered. It would forget which files it had just created. The system context was there, but something about how it was assembled wasn't working.
I knew I needed to improve the context pipeline. But I also knew that making changes to it without being able to measure the impact would be flying blind. I'd make a change, test it by hand with a few Telegram messages, think it was better, and have no way to verify. That's not engineering, that's guessing.
Why Evals Matter
I've written about evaluating LLMs before in more theoretical terms, the different evaluation types, when to use LLM-as-judge versus human feedback, the challenge of non-deterministic outputs. Building this system made all of that theory concrete.
The key insight from that article still holds: you cannot improve what you do not measure. But what I learned this time is more specific: the eval system doesn't just tell you whether your agent is good or bad. It tells you where the agent fails and gives you a tight feedback loop for iterating on fixes. Without it, you're debugging vibes.
Design Decisions
I had a few choices to make upfront, and each one shaped how the system turned out.
Real providers, no mocks. I considered using mock responses for fast, deterministic testing, but that defeats the purpose. I'm testing whether Claude (or Gemini) can maintain context given my system prompt and conversation history. A mock can't tell me that. Yes, it costs tokens and takes a few minutes to run. That's fine, I'm paying for the subscription anyway.
Assertion-based grading, no LLM-as-judge. For this use case, I don't need another LLM scoring responses on a fuzzy scale. I need to know: did the agent mention the file name? Did the file actually get created? Does it contain the expected code? Simple substring matches and filesystem checks. Deterministic, fast to evaluate, easy to debug when they fail.
TypeScript for the eval, bash for the pipeline. The agent itself is pure bash, and that's intentional, it runs on a NAS with nothing but a shell. But the eval system is developer tooling that only runs on my local env. TypeScript gives me proper types, good ergonomics for writing test cases, and a real module system. The bridge between them is thin: two small bash wrapper scripts that expose the existing build_prompt and append_topic_context functions for the TypeScript runner to call via execSync.
How It Works
Here's how the eval system relates to the production agent. Both use the exact same bash context pipeline, that's the whole point. The eval just replaces Telegram with scripted turns and adds assertions after each response.
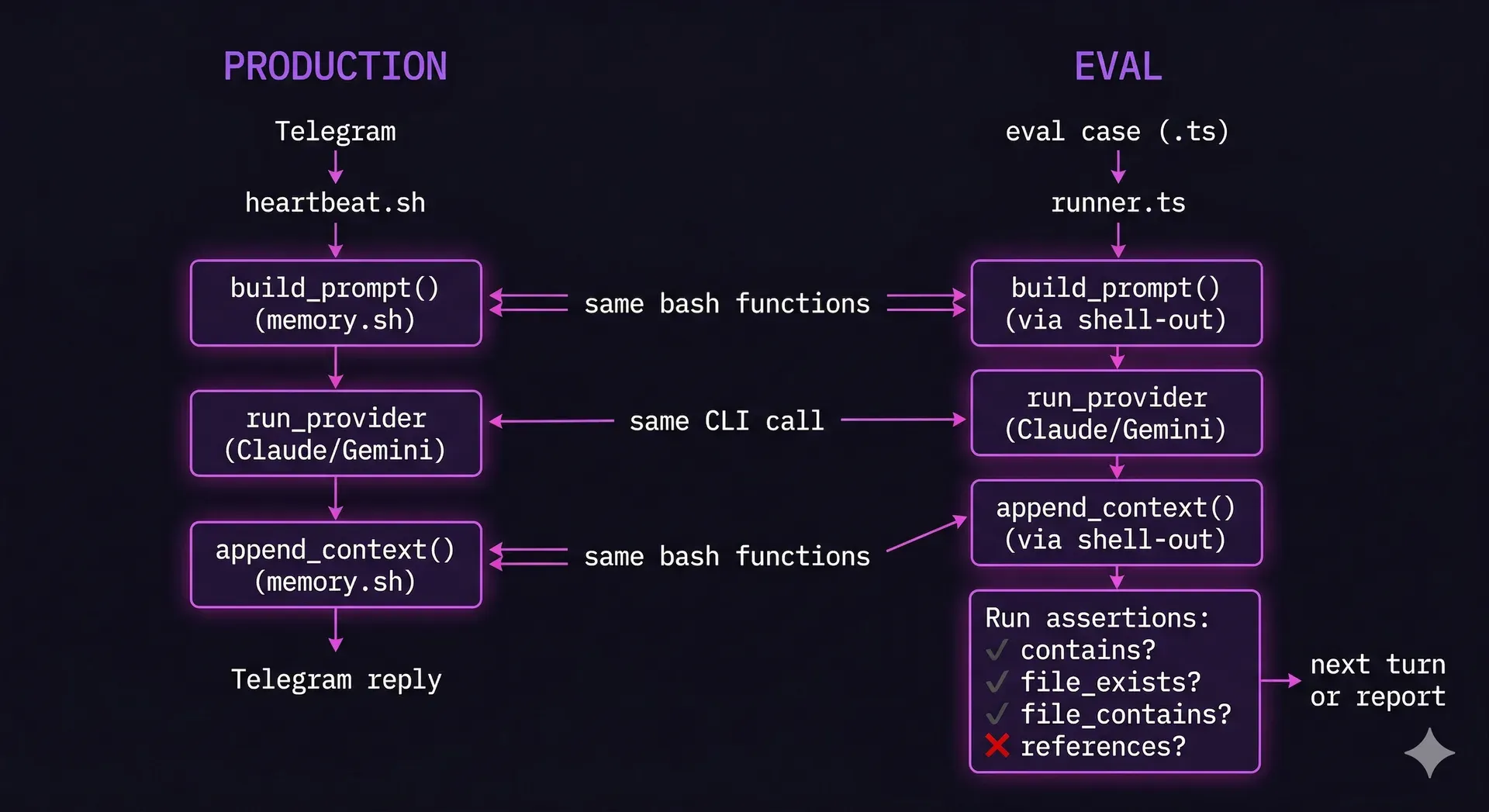
An eval case is a TypeScript file describing a multi-turn conversation. Each turn has a user message and a set of assertions. The runner iterates through the turns, calling the real bash context pipeline and the real AI provider for each one, accumulating context exactly as the production heartbeat does.
The assertion types are deliberately simple: does the response contain this string? Does this file exist? Does this file contain this pattern? Did the agent reference information from an earlier turn? That's it. No scoring rubrics, no weighted metrics. Either the assertion passes or it doesn't.
Running the eval is just pnpm test. It executes a reliability test first (20 mock messages to verify the orchestrator doesn't lose any), then the full eval suite against real providers.
What the Eval Immediately Revealed
The first run scored 14 out of 16 assertions. Not bad for a system I thought was broken. But the two failures were telling, both were references_turn assertions, checking whether the agent explicitly mentioned specific details from earlier turns. The agent was doing the work correctly (files were modified as expected) but wasn't narrating what it was doing. It would say "I've updated the function" instead of "I've updated hello.ts to accept a name parameter."
This pointed directly at the system prompt. The conversation continuity instruction was too vague, it said "reference specific details" but didn't tell the agent to name files, paths, and values explicitly. A one-line change to the system prompt made the difference.
But the eval revealed something bigger that I wasn't even looking for.
The Orchestrator Bug I Didn't Know About
While testing the agent end-to-end through Telegram, I noticed messages occasionally going missing. The agent would respond to some messages and completely ignore others. At first I blamed Telegram's API, then network issues, then timing.
The eval system's reliability test, which sends 20 numbered messages through the mock pipeline, passed perfectly. All 20 messages processed, zero lost. So the orchestrator loop itself was solid. The problem had to be external.
Running bash -x on the heartbeat during a live test revealed the real issue: a 409 Conflict response from Telegram. Multiple instances of the agent were polling simultaneously. Stale processes from previous sessions, stopped but not killed, were competing for updates. One instance would consume the message, the other would see nothing.
The fix was two-fold: auto-kill stale instances on startup, and flush the Telegram update queue so only messages sent after startup get processed. Neither of these would have been found by looking at the code. It took the eval system's reliability test proving that the orchestrator was correct, combined with a live failure, to triangulate the actual root cause.
The HTML Output Pivot
The eval also pushed me toward a design change I'd been vaguely thinking about. The original system truncated agent responses to 500 characters before storing them as context for the next turn. This was a crude fix to keep the context file from growing unbounded, but it was destroying information.
Once I could measure context retention, the fix became obvious: instead of truncating, have the agent produce structured output. Simple responses stay as plain text. Complex responses get split into a summary (stored as context and sent as a Telegram message) and a full HTML document (saved to disk and attached as a file in Telegram).
The summary is written by the agent specifically for continuity, it's information-dense, naming specific files, decisions, and values. Much better signal than the first 500 characters of whatever the response happened to be. And the HTML attachment means complex explanations can include tables, diagrams, and proper code formatting instead of being crammed into Telegram's plain text limit.
The Feedback Loop
Here's what I didn't expect: the eval system changed how I think about the agent. Before, improvements were intuitive, "I think this prompt is better." Now they're measurable. I change the system prompt, run the eval, and see a number go up or down. That tight feedback loop makes iteration fast and confident.
The eval suite is small right now, two multi-turn cases, a few dozen assertions. But it's already caught real issues and guided real improvements. As I add more cases, it becomes an increasingly honest mirror of the agent's actual capabilities.
The full implementation is in the ai-server-agent repository, the eval subsystem lives in the eval/ directory, and the reliability test is in test/. If you're building autonomous agents and you don't have evals yet, start with something simple. You'll be surprised what it reveals.